



UDP和TCP协议纪要
对于UDP和TCP协议,可以从一下切入点来记忆思考:
明确这两个协议在OSI中处于传输层,用于不同设备进程之间通信
报文段都是由头部+数据组成
面向报文和面向连接,这决定两个协议面向了不同的业务需求,面向报文的UDP不关心连接的可靠性,一定程度上保证了传输速率,面向连接的TCP恰好相反,因此一定程度上损失了传输速率,但大大保证了传输的可达性和安全性
简单头部和复杂头部,由面向不同业务的思路可以发现,由于不需要考虑可靠性,因此UDP的头部设计的非常精简,只占用8个字节,而TCP为了连接的可靠性,有三次握手四次挥手的复杂连接/断开过程,因此一般头部就占用20个字节,这还不考虑选项40字节的可变长度
交互通信的不同,也是由面向不同业务的思路可以发现,UDP不考虑可靠性,因此支持一对一,一对多,多对一,多对多,而TCP只在确定通信的两端一对一
UDP的首部特征
首部特征:
源端口号:在需要对方回信时选用,不需要时可用全 0 表示;2字节
目标端口号;2字节
长度:UDP 用户数报的总长度;2字节
校验和:检测 UDP 用户数据报在传输中是否有错,如果有错则丢弃。2字节
伪首部特征:
源地址;4字节
目标地址;4字节
保留位,一般为0;1字节
协议类型,UDP为17;1字节
UDP长度;2字节
易混淆的:伪首部中描述的字节,并不在传输过程中被占用包装数据,这些数据部分来自于更底层的IP协议,是实际头部的检验和用于计算数据的完整性的
TCP的首部特征
重点要记:想要清楚的理解和描述出三次握手和四次挥手,就必须必须必须把TCP首部特征记忆下来,包括每个控制位,这样才能在物理层面结合底层的协议去清晰的认知到整个TCP连接和断开的过程。如果不做到这一点,那么三次握手和四次挥手一会儿一个ACK,一会儿一个SYN容易让人不知所措,但是如果你知道SYN表示序号,而ACK表示确认序号的确认号,你会发现在整个过程中,都是围绕着序号和确认序号来连接/关闭,本身就没有这么复杂了
源端口和目的端口:各占 2 个字节
序号:占 4 字节,序号范围为 [ 0 , 232 -1] ,序号增加到 232 - 1 后又会回到 0 。在一个 TCP 连接中,传送的字节流中的每一个字节都要按顺序进行编号。
确认号:占 4 字节,表示期望收到对方下一个报文段的第一个数据字节的序号。例如 B 收到 A 的报文,序号值为 501 ,数据长度为 200 字节(序号 501 ~ 700),此时表明 B 正确收到了序号 700 及其之前的所有数据,因此 B 在发送给 A 的确认报文段中确认号的值为 701。
数据偏移:占 4 位,其所能表达的最大数字是 15 。数据偏移表示该数据报中数据的起始位置,由于数据报是由 首部+数据 组成,所以实际上就是指报文段的首部长度。数据偏移的单位是 32 位字(即以 4 字节长为单位),所以数据偏移的最大长度是 60 (15*4)字节,即 TCP 报文段的首部长度不能超过 60 字节,对应的选项长度不能超过 40 字节。
保留位:占 6 位,保留为今后使用,目前应置为 0 。
六个控制位:其作用分别如下:
紧急 URG (URGent):当值为 1 时,表明紧急指针字段有效,代表此报文中有紧急数据,应尽快传送,而无需按原来的排队顺序传送。
确认 ACK (ACKnowledgment):当值为 1 时,确认号有效;值为 0 时,确认号无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置为 1。
推送 PSH (Push):当值为 1 时,表示接受方应该将数据立即交付给应用进程,而不是等待缓存填满后再向上交付。
复位 RST (Reset):当值为 1 时,表明 TCP 连接出现严重差错,必须立即释放,然后再重新建立连接;也可以用来拒绝一个非法的报文段或拒绝打开一个连接。
同步 SYN (SYNchronization):在连接建立时用来同步序号。当 SYN = 1 而 ACK = 0 时,表明这是一个连接请求报文段;对方若同意建立连接,则应在响应的报文段中使 SYN = 1 和 ACK = 1 。
终止 FIN (FINis):当值为 1 时,表明此报文段发送方的数据已发送完毕,并要求释放连接。
窗口:占 2 字节,取值范围为 [ 0 , 216 - 1 ] 之间的整数。窗口字段保持动态变化,用于指明接收方允许发送方发送的数据量。上层的http协议通过此项来实现流控制
校验和:占 2 字节,校验的字段范围包括首部和数据。
紧急指针:占 2 字节,仅在 URG = 1 时才有意义,用于指明紧急数据的结束位置,位于结束位置之后的就是普通数据。
选项:长度可变,最长可达 40 字节。可用的选项有:最大报文段长度 ,窗口扩大选项、时间戳选项等。
TCP三次握手
TCP 建立连接的过程叫做握手,握手需要在客户和服务器之间交换三个 TCP 报文段
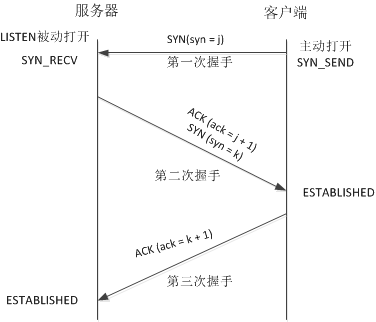 三次握手流程详解:
三次握手流程详解:
服务器进程 首先创建传输控制模块 TCB,然后进入 LISTEN(收听)状态,准备接受客户端的连接请求;
客户端进程 首先创建传输控制模块 TCB,然后发出连接请求报文段,此时同步位
SYN = 1,同时选择一个初始序号seq = x,之后进入 SYN-SENT(同步已发送)状态;服务端进程收到连接请求报文段后,如果同意建立连接,则发送确认报文段,此时 SYN 和 ACK 都置为 1,确认号
ack = x + 1,并为自己选择一个初始序号seq =y,之后进入 SYN-RCVD(同步收到)状态;客户端进程收到来自 服务端进程 的确认后,发出最后的确认,确认报文段的 ACK 为 1,确认号 ack = y + 1,序号 seq = x + 1。TCP 标准规定,ACK 报文段可以携带数据也可以不携带,如果不携带则该序号不被消耗,下一个数据报文段的序号仍然是 seq = x + 1。之后 客户端 进入 ESTABLISHED(已连接)状态;
三次握手叙述要诀,简单来说,三次握手,就是通信双方的三次报文,对于报文内容,可以通过SYN报文—>SYN-ACK报文—>ACK报文来梳理记忆。对于每段报文,从控制位(主要是同步位和确认位)的变化+序号/确认号的变化+状态变化来描述
TCP四次挥手
一个正在通信的TCP连接,通过四次挥手来关闭连接
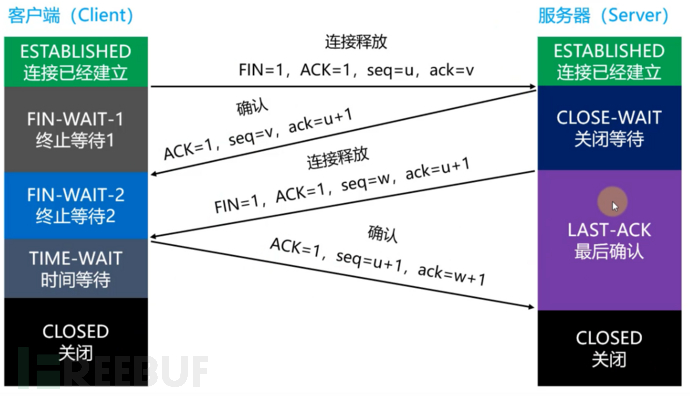 四次挥手流程详解
四次挥手流程详解
客户端进程 先主动关闭连接,此时需要发送连接释放报文段:首部终止控制位 FIN 为 1,序号
seq = u,其中 u 等于前面传送过的数据的最后一个字节的序号加 1 。之后 客户端 进入 FIN-WAIT-1(终止等待 1)状态;服务端收到连接释放报文段后立即发出确认报文段,确认号 ack = u + 1,序号 seq = v ,其中 v 等于前面传送过的数据的最后一个字节的序号加 1 。之后 B 进入 CLOSE-WAIT(关闭等待)状态,并通知高层应用进程。此时 TCP 连接处于半关闭状态,即 客户端已经没有数据需要发送,但如果 服务端发送数据,客户端仍要接收;
客户端接收到服务端发送的确认报文段之后,由FIN-WAIT-1状态变更为FIN-WAIT-2状态,等待服务端发送连接终止报文段
若高层应用进程已经没有数据要发送,则通知 服务端 释放 TCP 连接。此时 服务端 发出释放连接报文段:首部终止控制位 FIN 为 1,序号 seq = w(在半关闭状态下 B 可能又发送了一些数据),另外还需要重复上次已经发送过的确认号 ack = u + 1。之后 B 进入 LAST-ACK(最后确认)状态;
客户端 收到 服务端 的连接释放报文段后,发出最后确认报文段:确认位ACK 为 1,确认号
ack = w + 1,序号seq = u + 1,然后进入 TIME-WAIT(有时间限制的等待)状态;服务端收到来自 客户端 的最后确认报文段后进入 CLOSED(关闭)状态
经过两倍MSL(Maximum Segment Lifetime,最长报文段寿命)后,才进CLOSED状态
四次挥手叙述要诀:还是着重于报文段,虽然TCP是面向连接的,但它也是基于报文的,纵观整个断开状态,就是围绕着FIN报文—>ACK报文—>FIN-ACK报文—>ACK报文—>ACK报文来展开的,报文头部也是根据这些报文段来改变控制位以及确认号和序列号
随记
数据边界:实际上可以理解为数据格式,TCP基于字节流,描述的是没有数据边界,进而可以理解为TCP连接不限制数据的格式,而是把数据当成流一样传输
如何理解TCP面向字节流和UDP面向报文
UDP面向报文:
在发送端,当用户消息通过UDP协议传输时,操作系统不会对用户消息进行拆分,在组装好UDP头部后就交给网络层处理,所以UDP发送出去的报文的数据部分就是一个完整的用户消息,每一个UDP报文就是一个用户信息的边界
在接收端,虽然接收时可能会发生多个包一起接收的情况,但是接收端会使用队列来存储UDP报文,每一个元素就是一个独立的UDP报文,操作系统通过获取队列的元素来读取UDP报文数据,因此也不会出现消息边界不明确的情况
总结来说,UDP面向报文的思想是始终将完整的用户信息保留,无论是发送方还是接收方,都会有响应的机制来确保完整的用户信息,所以说它是面向报文的
TCP面向字节流:
在发送端,当用户信息通过TCP协议传输时,操作系统会对用户信息进行拆分,被拆分的数据可能会放到不同报文中传输
在接收端,由于在发送端用户信息被拆分了,这时如果不知道报文中用户消息的长度(也就是无从得知信息的边界),就无法拼接出完整的用户信息,因此我们不能认为一个用户信息对应一个TCP报文,所以说TCP是面向字节流的
总结来说,TCP面向字节流是因为TCP报文中无法获取完整的用户信息,无论是发送方还是接收方,都没办法获取完整的用户信息
评论区